Diagnosis and Challenge
In times of go horsing and the need to deliver software products quickly, sooner or later, we will encounter chaotic scenarios.
I feel there is a cycle where companies and professionals are strategically shaped to work with a focus on speed, while in other periods, there is a demand for professionals capable of fixing the problems created during phases of competition, product validation, and business growth.
One of my most remarkable experiences was restructuring the team and all the software that were part of a retail startup’s platform.
At the time, monoliths were being crucified, service-oriented architecture (SOA) had failed, and microservices were becoming popular.
The solution is simple, right? Just turn everything into microservices, and all performance and scalability issues will magically disappear
Magical phrases like the one above seem to make sense. In fact, the engineers at this startup followed exactly that path—except they forgot that in software architecture, everything has its pros and cons.
With this in mind, let’s go through a Pros and Cons analysis.
Typically, a pros vs. cons analysis should be done beforehand, but since it wasn’t, and I’m telling the story now, I’ll do a post-mortem analysis. Additionally, this analysis will be more accurate because it reflects the actual reality.
Pros:
The deployments of the applications became independent, making updates faster.
The platform became faster, and performance improved significantly for users.
The platform was ready to scale and handle higher user traffic.
It became easier to create new features, especially simpler ones that previously would have taken longer due to coupling and dependencies within the same codebase.
Cons:
The incorrect separation of some domains created interdependencies between services, meaning some flows became distributed monoliths.
The complexity of maintaining the platform increased.
Some single points of failure were created; it was common for an error to cause issues in other parts of the platform, leading to a full system outage. Additionally, distributed failure points made diagnosing root causes more difficult.
Although it became easier and faster to create new features, maintaining them became more difficult and costly.
If the platform became faster, more scalable, and easier to develop new features, then the problem was solved, right?
Think again!
Maintenance became more difficult and required a larger, multidisciplinary team. To make matters worse, developers started jumping ship, leaving the problems for those who came next and taking with them all the knowledge of business rules.
On average, the platform was down twice a day.
When I arrived, there were three developers: a backend developer, a frontend developer, and an intern.
As soon as I joined, the backend developer was fired because he made a critical mistake in production, causing multiple customers to be incorrectly charged on their credit cards—some receiving more than nine incorrect charges.
To make things even more challenging, the frontend developer had several gaps in both hard and soft skills.
It didn’t take long to realize I had walked into a mess. After some reflection, I decided to make a bold proposal to the CEO.
I knew that if I stayed alone, I would just work endlessly and put out fires. However, I also knew skilled developers, and I would be capable of leading them—provided I had a plan and clear direction.
I proposed leading a new team, provided I had the freedom to shape the culture, implement changes, and make the corrections I deemed necessary.
Going Back in Time
How did you end up accepting a job in such a chaotic place?
The problem with chaotic workplaces is that no one usually tells you how bad they are—either because the interviewers don’t know or because they deliberately hide the truth.
In the first case, it’s easy to figure out. A few well-placed questions, and the interviewers unknowingly reveal the reality.
The real challenge comes in the second scenario, which, unfortunately for me, was exactly the case.
For those curious, here are the questions I ask to understand where I’m about to invest my time, effort, and mind:
1 - How many developers are on the team?
The math here is simple: if the platform is large, packed with features, and has only a few developers, then there’s a work overload. This also signals a high turnover rate.
2 - What is the biggest current technical challenge?
This helps determine whether the team is chasing after their own problems or actually innovating.
In environments that recently migrated to microservices, it’s common to see issues like:
Single points of failure
Data inconsistencies
Blind spots due to failures with no monitoring
Increased latency
Communication problems between services
3 - What software development cycle do you follow?
This question helps assess the maturity of the software development and product teams.
Depending on the response, it might also indicate that the team operates in go horsing mode.
4 - How are tasks defined?
Understanding how tasks are defined and prioritized can reveal whether decision-making is top-down and how much pressure there is around delivery deadlines.
Action Plan and Execution
So, how did I recover the platform?
The first step was assembling a team of skilled developers who not only understood the existing problems but were also engaged in solving them.
No good developer would accept working in a broken system unless my strategic and tactical plan was strong enough to convince them.
Strategic Plan:
Have a clear diagnosis of critical points, ensuring clarity on urgent issues and risks.
Define and implement processes, with a strong emphasis on establishing a well-structured software development cycle.
Hire the right profiles for short, medium, and long-term needs.
Tactical Plan:
After identifying the platform’s weak points, I was able to prioritize them based on urgency and risk. I detailed the causes and effects of these failures and documented what could be done in the short, medium, and long term.
I already had a playbook of processes and prior experience with software development cycles in other companies. We knew exactly how we would operate, test, deliver, and maintain software projects.
We established processes to:Inform all company departments about software changes
Identify and classify risks
Estimate effort
Plan objectives
With a clear understanding of the right developer profiles for this plan, my task was to convince them to join this journey of restructuring an entire platform.
Execution began with the local development environment.
Remember that developer who made a mistake while implementing a payment integration and got fired?
That situation stuck with me, and deep down, I knew the problem ran much deeper…
I discovered that the developer didn’t have the proper conditions to implement the payment integration safely. In short, he had no way to test if his implementation was working because the platform had been migrated to microservices, and locally, it was too complex to run all the services just to go through the entire flow and reach the payment step.
The first big problem we solved was making the local development environment consistent with production, allowing developers to implement and test any functionality without friction. This brought stability, confidence, and productivity to the entire team.
When the new developers arrived, they were able to understand the platform quickly and become productive almost immediately—thanks to the well-defined software development cycle we had put in place.
With skilled developers who knew exactly what needed to be done, I took the lead in negotiating deadlines and requirements, acting as the bridge between business and development. My focus was ensuring that everyone could do their job effectively without unnecessary obstacles.
Unfortunately, there was a lot of work to be done, and during the first three months, I was hands-on, writing code to stabilize the platform, refactoring poorly designed microservices, and developing critical foundational services.
Stabilization Phase
Stabilization itself took two months. During this period, platform outages were common during peak hours, but we had contingency plans in place to restore services quickly while working on permanent solutions.
In six months, the platform was revamped, and we were building new features at an increasingly productive and consistent pace in terms of quality.
By then, we had established solid quality guidelines: code reviews, testing processes, and continuous delivery. We also proactively detected errors in production, ensuring users rarely noticed when something went wrong.
Achieved Results
I remember it like it was yesterday—the day I went out for lunch, and no one called me to complain that the platform had crashed. That was the moment I realized the entire plan had worked, and the platform was finally recovered.
At the time, I didn’t have as much clarity about metrics as I do now, but the ultimate result was my own peace of mind as the technical lead responsible for the platform.
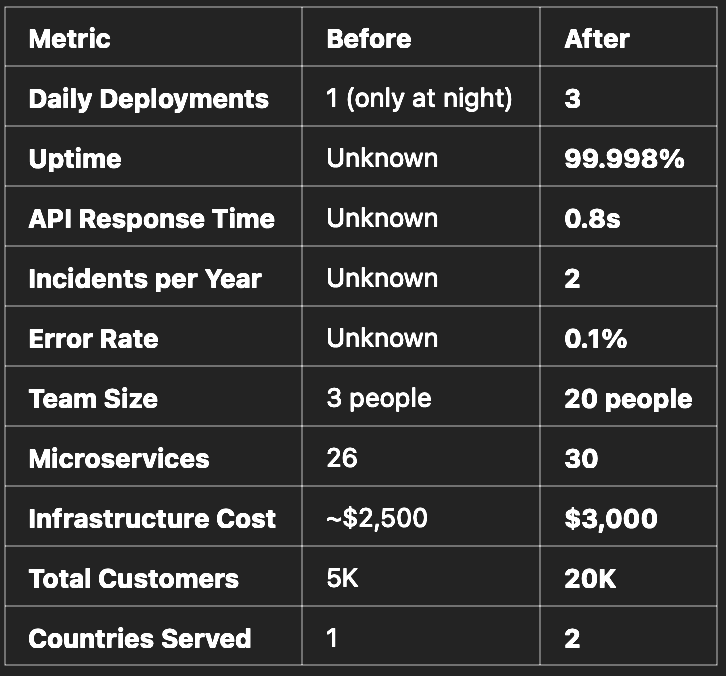
That said, I knew that both technical and business metrics needed to be tracked. Here are the before and after numbers following the platform’s recovery:
Before & After: Platform Recovery Metrics